Java Web Crawler
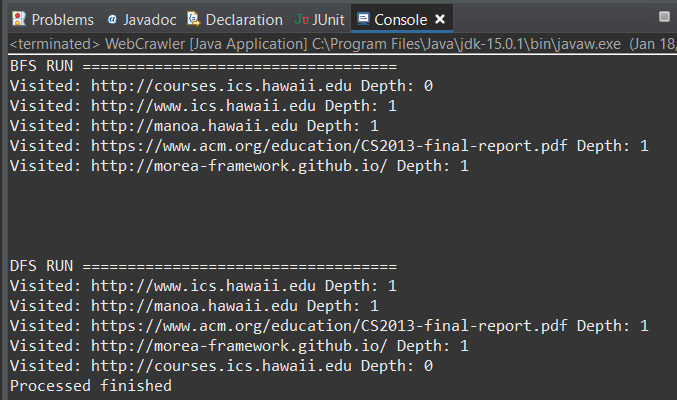
This is a simple webcrawler Java program that takes 2 command-line arguments. The 1st argument is the HTML URL that will be crawled, and the 2nd argument is the depth that the HTML will be crawled. Once it has “crawled” through all the HTML links, it will print the list to the console in a breadth-first search (BFS) and depth-first search (DFS) fashion.
This was my first project where I worked with others and collaborated to make the code function. During the process of this project, we mapped out the general design for the code. We made pseudocodes for the essential methods of the code. And then as we coded we went to Stack Overflow> and GeeksforGeeks for assistance.
This was a very beneficial project, learning to extract links from an HTML, using regular expressions to filter through input sequence, performing breadth-first search and depth-first search algorithm, and the use of hashtables and linked lists data structures. This put alot of the material, learned from 211, simultaneously to practice. There were some components, such as the graph traversal algorithm, that I am still unsure about and hopefully will be addressed in the ICS 311 course.
Source: Louie808/Java_WebCrawler.
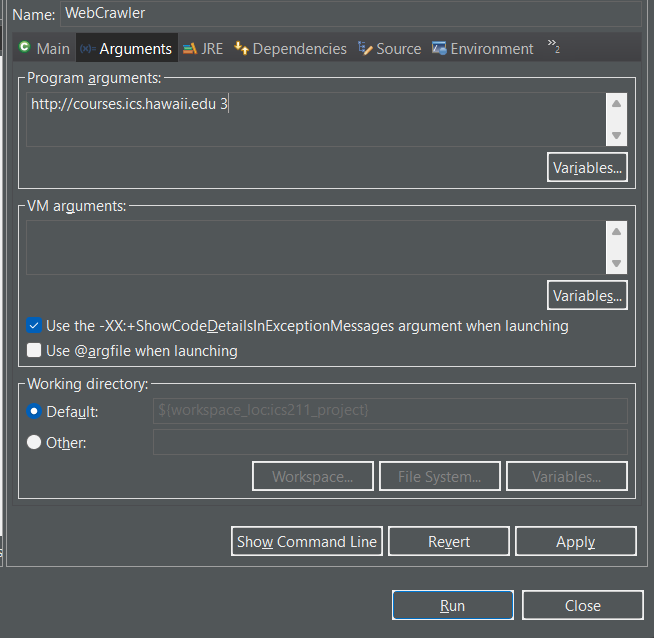
Command line argument
Start of Breadth-First

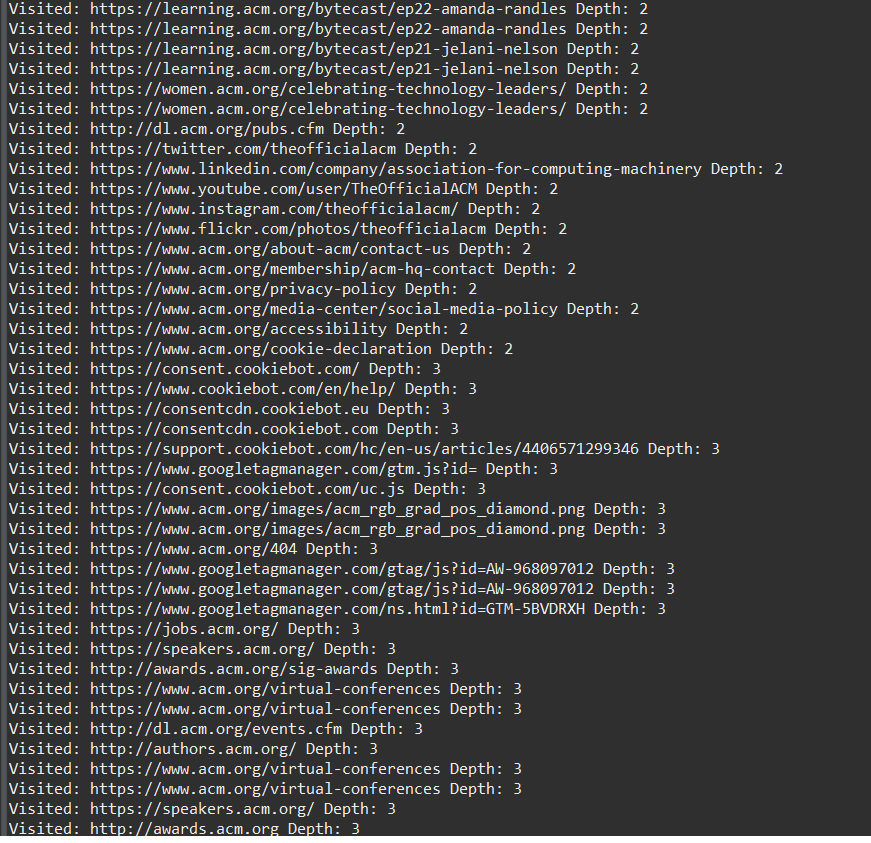
Console keeps printing even through depth of 2
Breath-First and Depth-First with a depth of 1